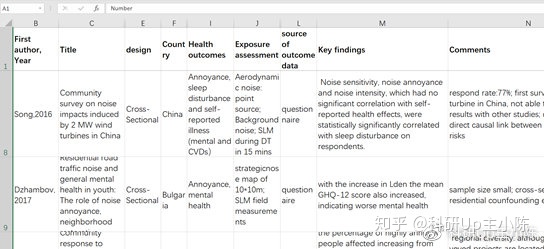
持续更新题目列表
Outline
• 什么时候使用 BFS
• 二叉树上的 BFS
• 图上的 BFS
• 矩阵上的 BFS
• 拓扑排序 Topological Sorting
什么时候应该使用BFS?
图的遍历 Traversal in Graph
• 层级遍历 Level Order Traversal
• 由点及面 Connected Component:其实就是判断点有没有联通
• 拓扑排序 Topological Sorting
简单图最短路径 Shortest Path in Simple Graph
非递归的方式找所有方案 Iteration solution for all possible results
P.S. 如果题目问最短路径 除了BFS还可能是什么算法? 如果问最长路径呢?
最短路径
简单图 → BFS
复杂图 → Dijkstra, SPFA, Floyd(一般面试不考这个)
最长路径
图可以分层 → Dynamic Programming
分层:比如走到第i一定会经过第 i-1 层(棋盘格子图是典型的例子)
不可以分层 → DFS
Code Template
我一般使用双端队列,没试过用普通Queue去做。按照大佬的说法,那个Queue主要是服务于多线程。如果队列里没有东西然后POP的话,会block在那儿,结果就是超时TLE。所以一般还是用collections.deque。
P.S. 双端队列内部实现使用的是双向链表。队列用的链表,栈用的数组,因为它就是在尾巴上进行操作。或者两个队列轮着换来做,这样相当于栈。
关于deque一般也就用popleft和append,很少用到它的appendleft和pop。用deque两个好处,一个就是快,Queue它服务于多线程,会加锁,所以会慢一些。以上说的是python,Java的queue没问题。
然后BFS的思路用语言说可以总结成这么两步:
创建一个队列,并把起点放置进去
while队列不空,弹出队头,将它的邻居加入队列。(如果是图需要哈希表来防止访问已经到过的节点)
1 | from collections import deque |
If we care about level
1 | from collections import deque |
BFS Key Points
使用队列作为主要的数据结构 Queue
思考:用栈(Stack)是否可行?为什么行 or 为什么不行?
是否需要实现分层?
需要分层的算法比不需要分层的算法多一个循环
Java / C++: size=queue.size()
如果直接 for (int i = 0; i < queue.size(); i++) 会怎么样?
BFS in Binary Tree
Binary Tree Level Order Traversal : https://leetcode.com/problems/binary-tree-level-order-traversal/
Binary Tree Serialization (M+Y) https://leetcode.com/problems/serialize-and-deserialize-binary-tree/
P.S. 什么是序列化?
将“内存”中结构化的数据变成“字符串”的过程。
序列化:object to string
反序列化:string to object
什么时候需要序列化?
将内存中的数据持久化存储时
内存中重要的数据不能只是呆在内存里,这样断电就没有了,所需需要用一种方式写入硬盘,在需要 的时候,能否再从硬盘中读出来在内存中重新创建
网络传输时
机器与机器之间交换数据的时候,不可能互相去读对方的内存。只能讲数据变成字符流数据(字符串) 后通过网络传输过去。接受的一方再将字符串解析后到内存中。
常用的一些序列化手段:
• XML
• Json
• Thrift (by Facebook)
• ProtoBuf (by Google)
序列化算法
一些序列化的例子:
• 比如一个数组,里面都是整数,我们可以简单的序列化为”[1,2,3]”
• 一个整数链表,我们可以序列化为,”1->2->3”
• 一个哈希表(HashMap),我们可以序列化为,”{\”key\”: \”value\”}”
序列化算法设计时需要考虑的因素:
• 压缩率。对于网络传输和磁盘存储而言,当然希望更节省。
• 如 Thrift, ProtoBuf 都是为了更快的传输数据和节省存储空间而设计的。
• 可读性。我们希望开发人员,能够通过序列化后的数据直接看懂原始数据是什么。
• 如 Json,LintCode 的输入数据
Binary Tree Level Order Traversal II https://leetcode.com/problems/binary-tree-level-order-traversal-ii/
Binary Tree Zigzag Level Order Traversal https://leetcode.com/problems/binary-tree-zigzag-level-order-traversal/
Flatten Binary Tree to Linked List https://leetcode.com/problems/flatten-binary-tree-to-linked-list/
BFS in Graph
和树上有什么区别?
Ans: 图意味着有环,所以需要一个哈希表来记录已访问的节点,防止重复访问。
Problems:
Clone Graph (F) https://leetcode.com/problems/clone-graph
Word Ladder https://leetcode.com/problems/word-ladder/
Word Ladder II https://leetcode.com/problems/word-ladder-ii/
最典型的BFS问题 —— 隐式图 (Implicit Graph) 最短路径
BFS in Matrix
矩阵与图有什么区别呢?
图 Graph
N个点,M条边
M最大是 O(N^2) 的级别
图上BFS时间复杂度 = O(N + M)
• 说是O(M)问题也不大,因为M一般都比N大
所以最坏情况可能是 O(N^2)
矩阵 Matrix
R行C列
RC个点,2RC 条边(每个点上下左右4条边,每条边被2个点共享)。
矩阵中BFS时间复杂度 = O(R * C)
Problems:
Number of Islands https://leetcode.com/problems/number-of-islands/
Topological Sorting
几乎每个公司都有一道拓扑排序的面试题。
插一嘴,能够用 BFS 解决的问题,不要用 DFS 去做。
因为用 Recursion 实现的 DFS 可能造成 StackOverflow! (Iteration 的 DFS 一来你不会写,二来面试官也看不懂)
算法:
入度(In-degree):
有向图(Directed Graph)中指向当前节点的点的个数(或指向当前节点的边的条数)
算法描述:
统计每个点的入度
将每个入度为 0 的点放入队列(Queue)中作为起始节点
不断从队列中拿出一个点,去掉这个点的所有连边(指向其他点的边),其他点的相应的入度 - 1
一旦发现新的入度为 0 的点,丢回队列中
拓扑排序并不是传统的排序算法 一个图可能存在多个拓扑序(Topological Order),也可能不存在任何拓扑序。
拓扑排序的四种不同问法
求任意1个拓扑序(Topological Order)用上面的BFS思路即可
问是否存在拓扑序(是否可以被拓扑排序) 用上面的BFS思路即可
求所有的拓扑序 DFS
求是否存在且仅存在一个拓扑序 Queue中最多同时只有1个节点
还有一种:
求最小拓扑序(alien dictionary)
Problems:
Course Schedule https://leetcode.com/problems/course-schedule/
Course Schedule II https://leetcode.com/problems/course-schedule-ii/
Alien Dictionary https://leetcode.com/problems/alien-dictionary/
考点1:如何构建图 考点2:如何存储图 考点3:如何拓扑排序
Conclusion
• 能用 BFS 的一定不要用 DFS(除非面试官特别要求)
• BFS 的两个使用条件
• 图的遍历(由点及面,层级遍历)
• 简单图最短路径
• 是否需要层级遍历
• size = queue.size()
• 拓扑排序须掌握
• 坐标变换数组
• deltaX, deltaY
• inBound